I was the Product Designer/Manager and Lead AI/Backend Engineer on this project. This is my fork as I continue to develop the project.
Here I will detail the initial phase we completed as part of the AI Dallas Summer Program 2025. I plan to continue to produce more articles describing my experiences as I develop this project further.
Introduction
During the Dallas AI Summer Program 2025, our team embarked on an ambitious eight-week journey to solve one of the most frustrating aspects of modern digital interactions: the breakdown between chatbots and humans. What started as a simple observation about user frustration evolved into VIA, a comprehensive platform that reimagines how AI and human intelligence can work together.
This page provides an overview of building VIA, exploring our technical decisions, architectural challenges, and the lessons learned while developing a Human-in-the-Loop (HITL) system that actually works.
The Real World Problem
🚨 The Frustration Loop
Humans get frustrated when interacting with AIs, especially when they are forced to use chatbots for support. Current systems lack intelligent escalation pathways and fail to learn from human expertise, creating a cycle of poor experiences.
Our research revealed several critical pain points in existing chatbot implementations:
These statistics pointed to a fundamental flaw in how we think about AI-human collaboration. Instead of viewing humans as fallbacks for AI failures, we realized they should be integral partners in the intelligence pipeline.
Our Solution Approach
✅ The VIA Framework
VIA monitors chatbot-user interactions for warning signs, intelligently escalates to the "best" human to resolve issues, and incorporates resolutions into a feedback loop to improve both AI and human performance.
Our solution centers around three core principles:
1. Proactive Monitoring
Rather than waiting for explicit user complaints, VIA continuously analyzes conversation sentiment, response quality, and user behavior patterns to identify potential issues before they escalate.
2. Intelligent Human Routing
When escalation is needed, VIA doesn't just route to the next available agent. It considers expertise, workload, employee well-being, past performance with similar issues, and even time of day to find the optimal human match.
3. Continuous Learning Loop
Every interaction becomes a learning opportunity. Successful resolutions are analyzed and integrated back into the system, improving both AI responses and human agent preparation for future similar scenarios.
Product Architecture
We built VIA using modern agentic frameworks, specifically LangChain and LangGraph, to create a system where intelligent agents can collaborate seamlessly while maintaining clear separation of concerns.
The system architecture follows a microservices approach where each agent operates independently but can communicate through a central orchestration layer. This design allows us to upgrade individual agents without affecting the entire system.
The Four Core Agents
VIA's intelligence comes from the coordination of four specialized agents, each with a specific role in the human-AI collaboration pipeline:
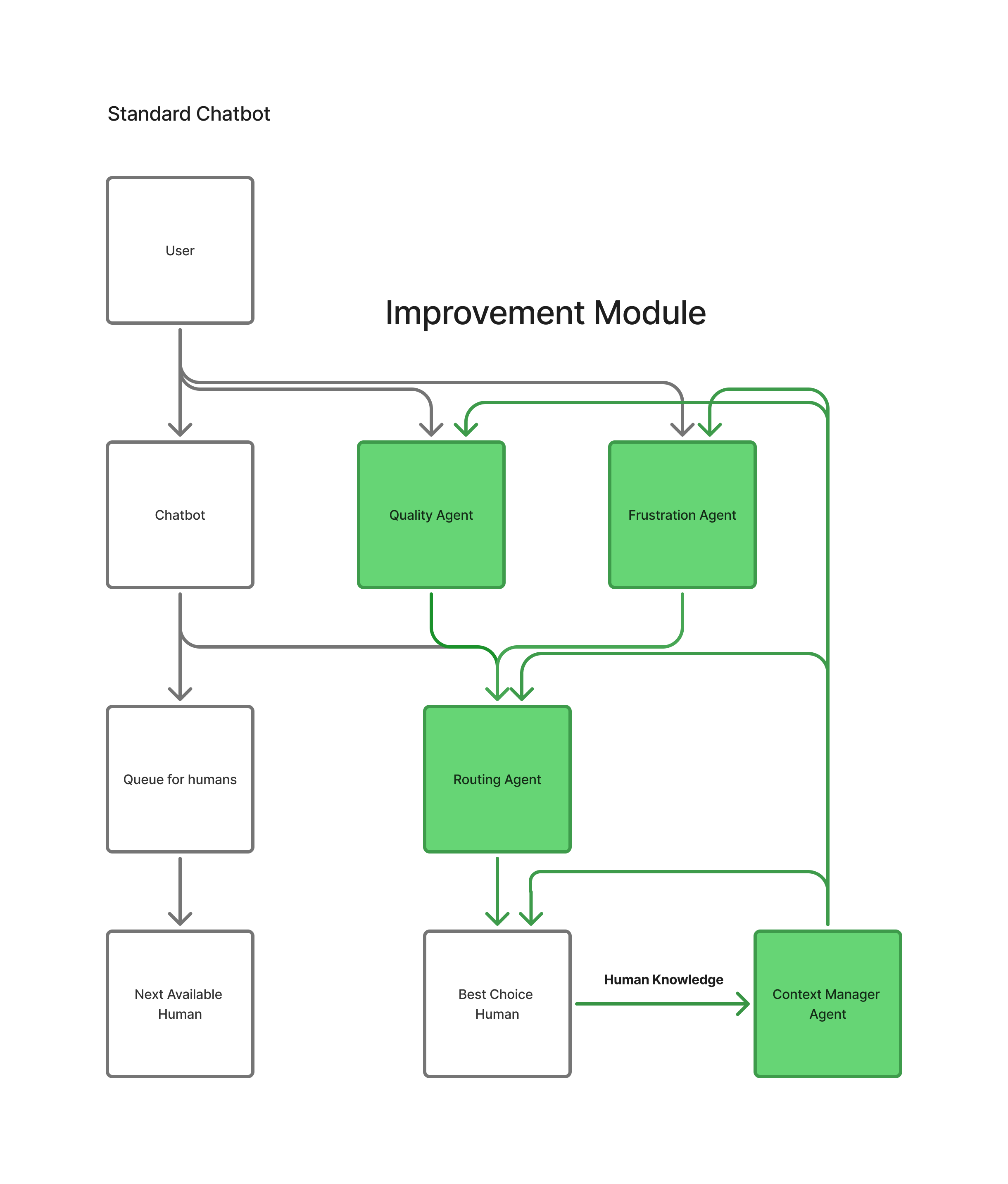
Frustration Agent
The Frustration Agent acts as our early warning system, continuously monitoring user inputs for signs of mounting frustration or dissatisfaction.
Quality Agent
Before any chatbot response reaches the user, the Quality Agent evaluates its adequacy and potential impact.
Routing Agent
When human intervention is required, the Routing Agent performs the critical task of selecting the optimal human agent.
- Current workload and availability
- Historical performance with similar issues
- Employee wellbeing and stress levels
- User frustration level and urgency
- Time zone and language preferences
- Recent feedback and success rates
Context Manager Agent
The Context Manager ensures that both AI agents and human representatives have access to all relevant information for each interaction.
Agent Demo
Below are screenshots from our demo showing the agents in action. I created a simple Gradio app and hosted it on Hugging Face Spaces: VIA Agent Demo.
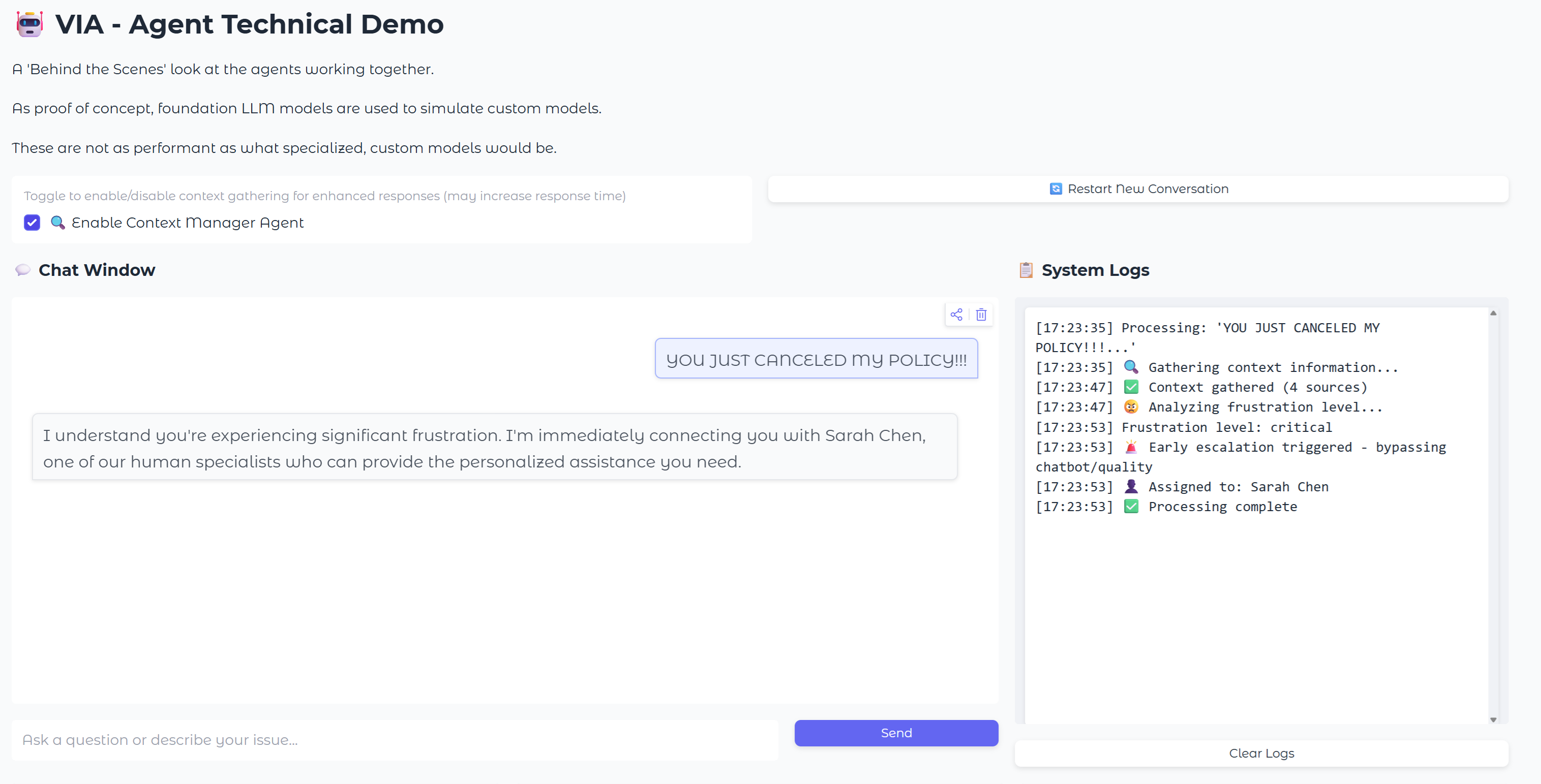
Demo Walkthrough
Let's walk through how each component of VIA works in practice, using screenshots from our technical demo.
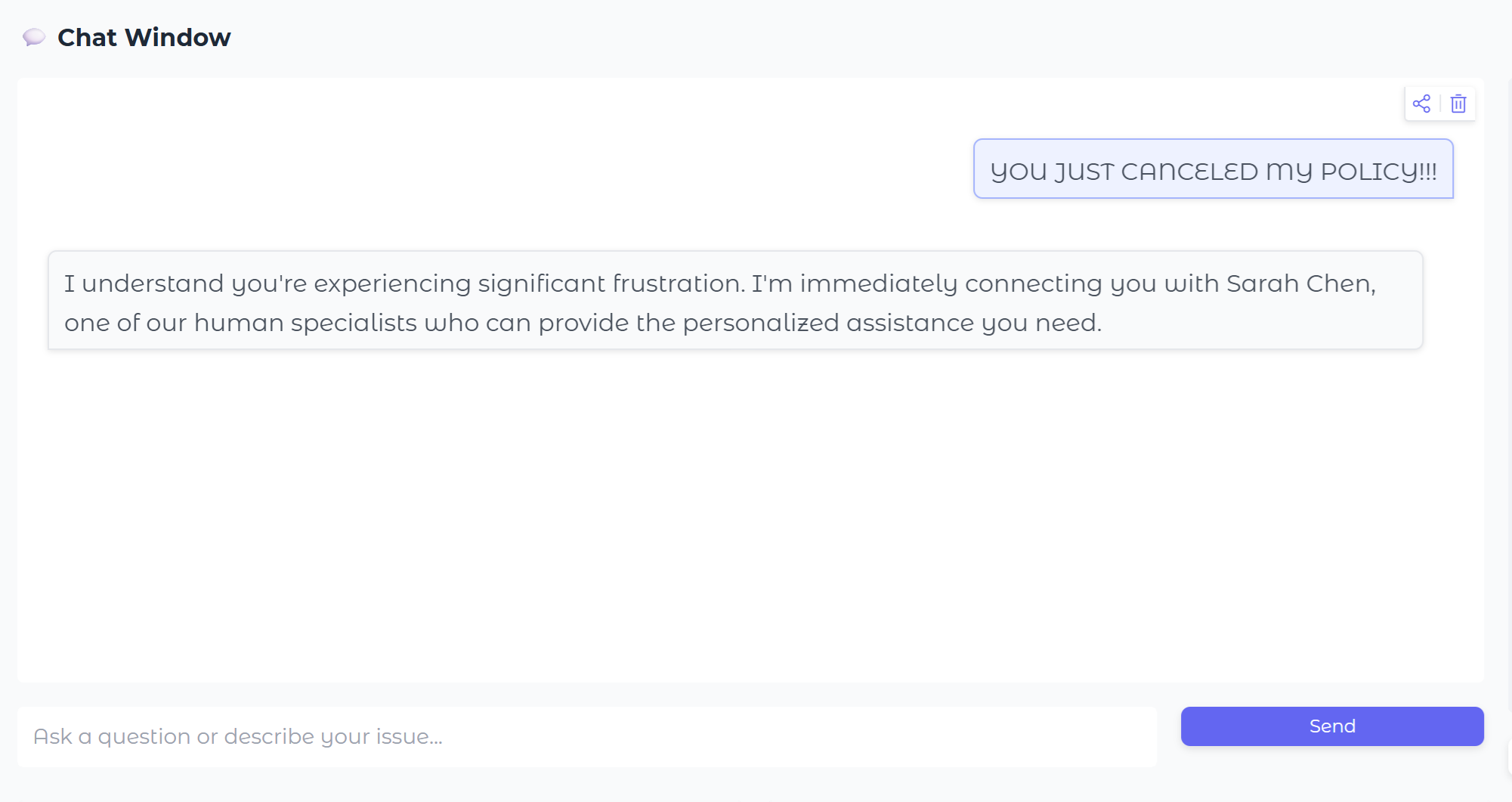
Chat Window
Our concept is that this design can improve any chatbot, including pre-existing ones, and for this prototype we had Gemini pretend to be an Insurance Company support chatbot.
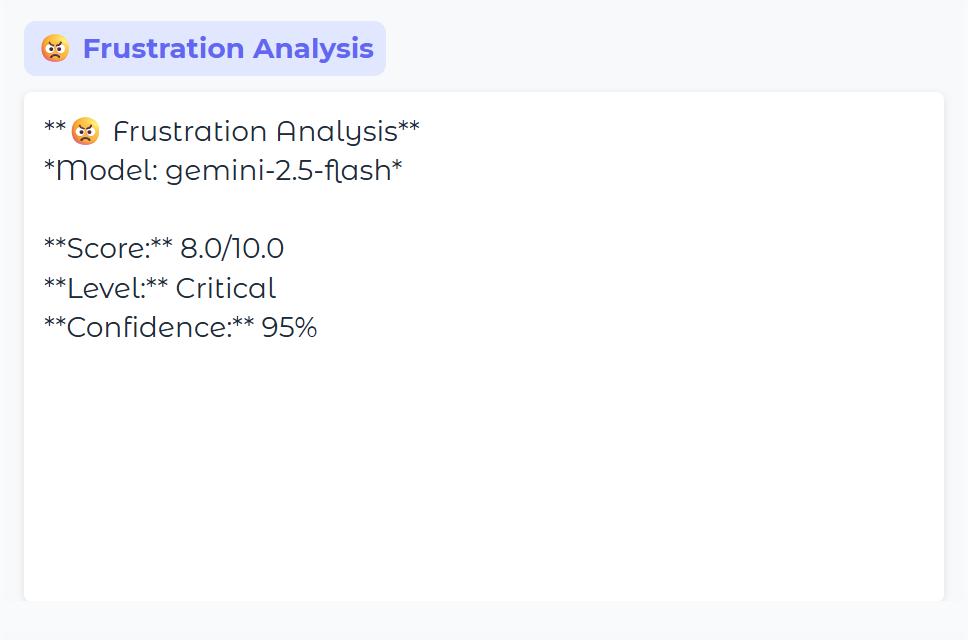
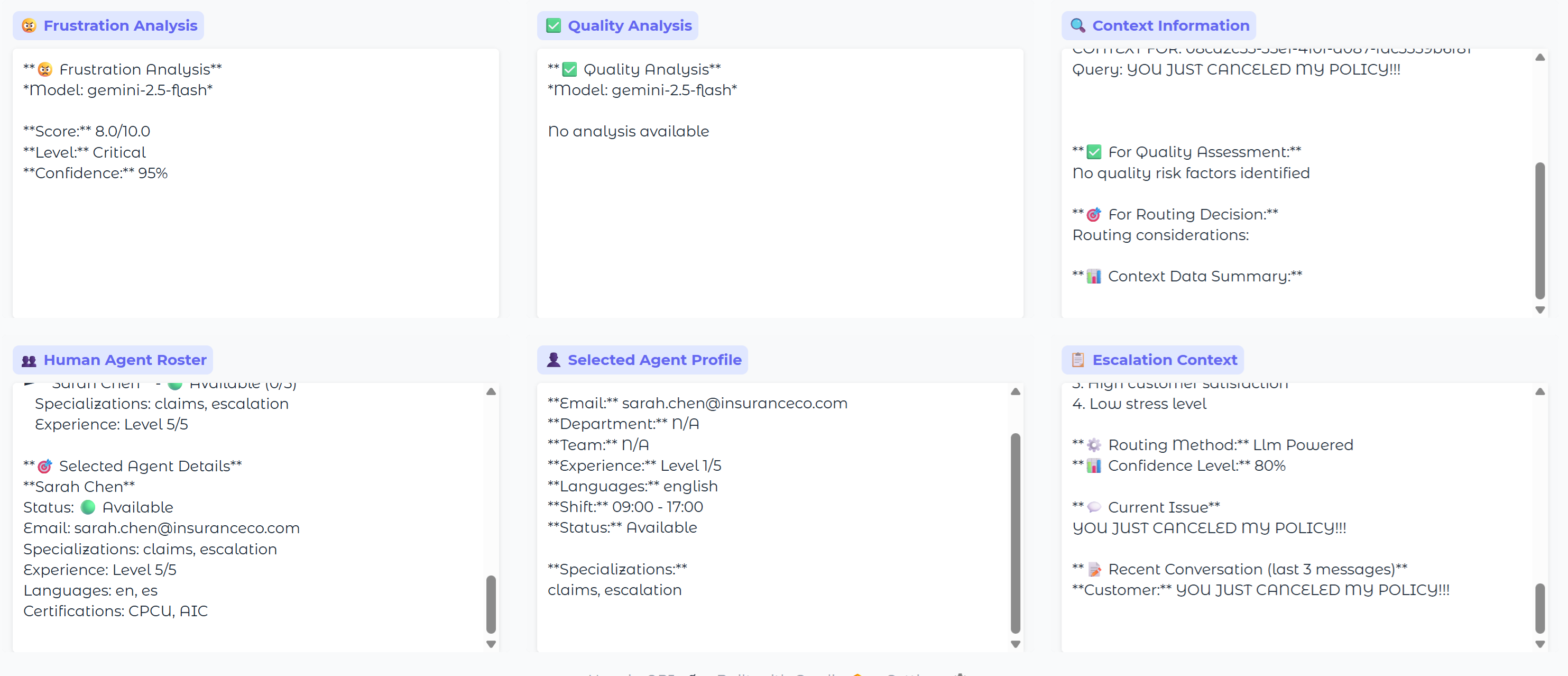
Frustration Analysis
This agent reviews the user input before it reaches the chatbot, looking for signs of frustration, which in this case was ALL CAPS, as you can see above in the chat window.
Gemini scores the frustration on a scale of 1 to 10, and if the threshold is exceeded (we use 7 in the config .yaml file), then escalation occurs.
Frustration score: 8.0/10 - Escalation triggered
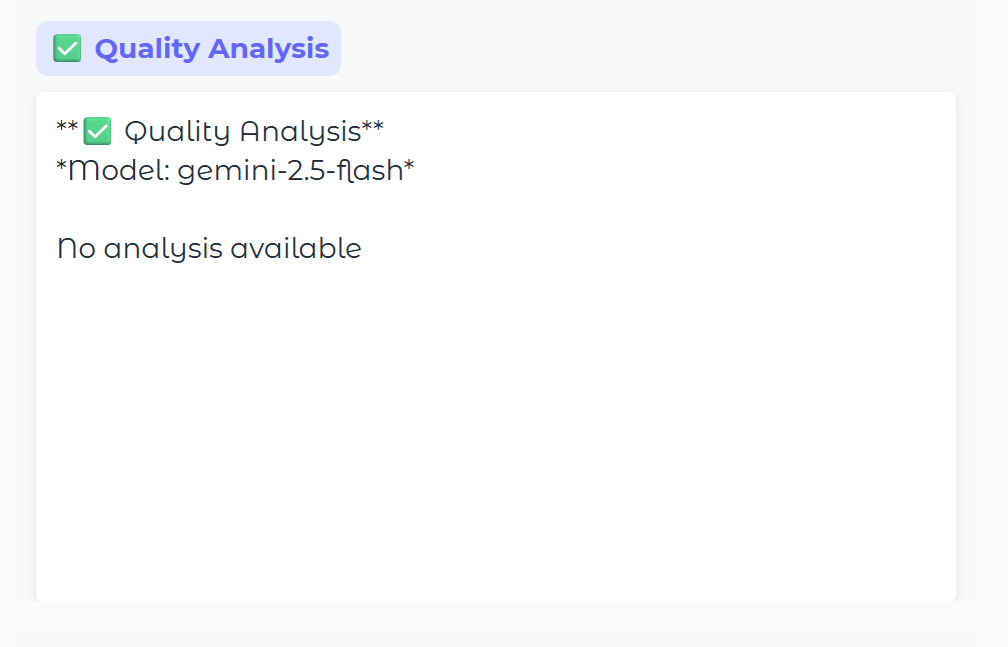
Quality Analysis
The Quality Agent in a similar manner intercepts and reviews the chatbot's output back to the user, with Gemini rating it on various factors.
In this case, there is no quality analysis because the frustration agent escalated and pre-empted any response from the chatbot.
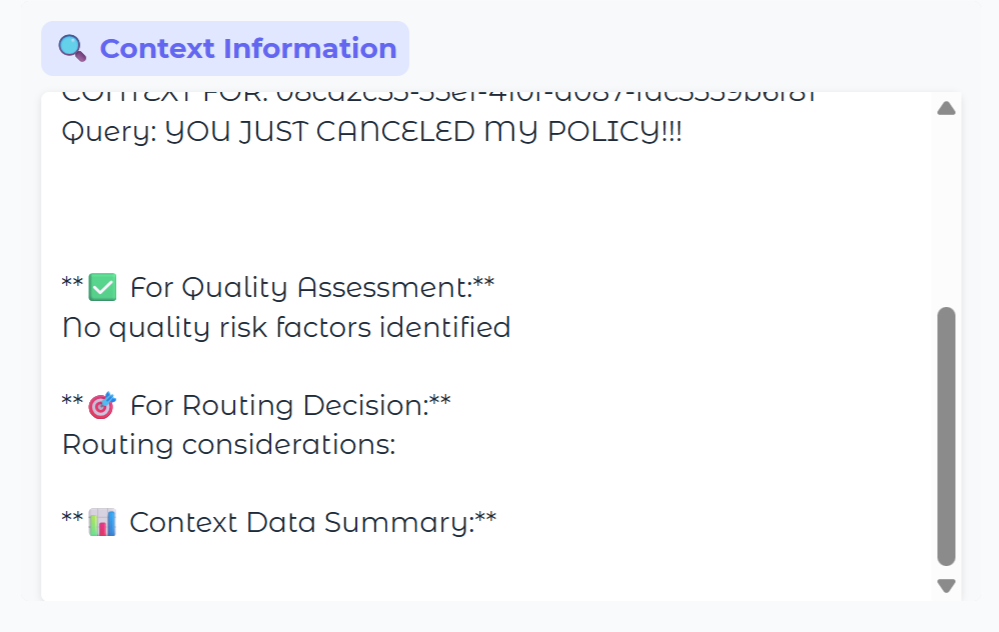
Context Management
The Context Manager is one of the keys to our system, but needs a lot of work. It currently relies on multiple SQL queries and is not very fast or efficient.
When complete, though, it will deliver relevant information to the other AI agents and to the human agents in addition to integrating key human insights back into the system in a continuous loop.
- User interaction history
- Similar resolved cases
- Product knowledge integration

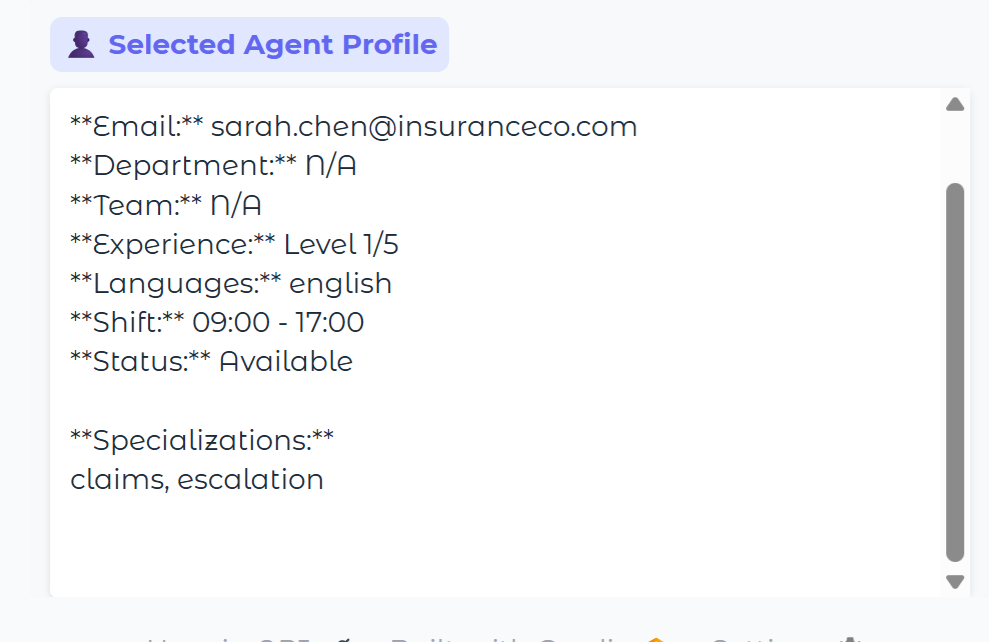
Intelligent Human Routing
When escalation is needed, the Routing Agent analyzes available human agents and selects the optimal match. This is another key feature to our system, and again, one that needs a lot of work.
In this demo example, agent Sarah Chen was selected based upon various factors that the model scored and any other context provided.
She has 5/5 experience and "escalations" are one of her areas of expertise, so she gets selected a lot in the demo for frustation escalations. This is something that needs be better modeled to balance the workload.
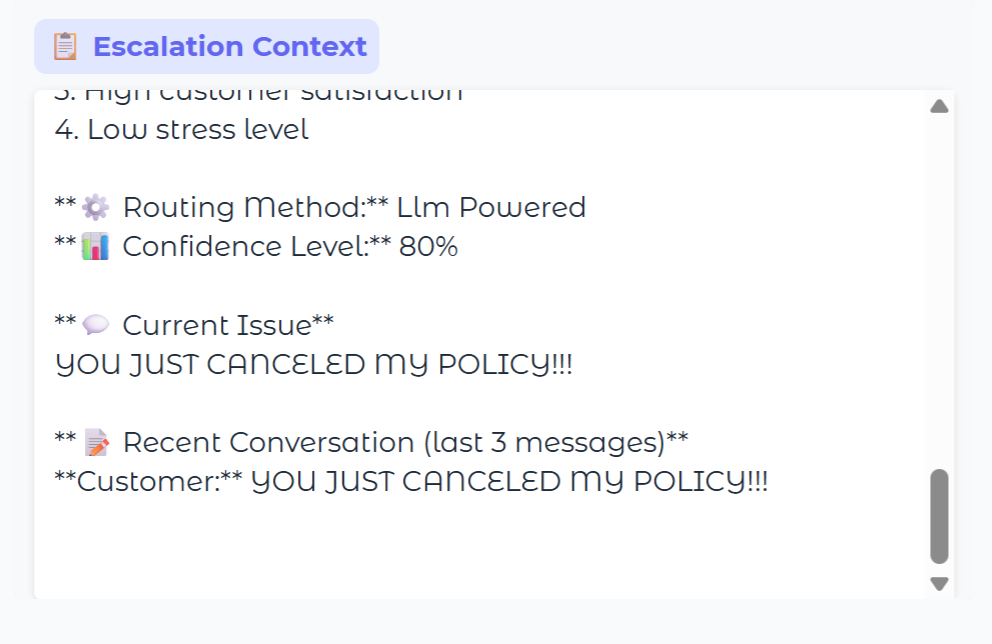
Sharing the Context and Reasoning
Another key feature of our concept is that the reason behind decisions are integrated into the context management system and shared.
For example, when it is escalated to a human, the human gets to see why this query was escalated "Frustration Score: 8.0" and why they were chosen to receive this escalation along with transaction history, any relevant info from knowledge base, and other context.
Ideally, the finalized UI will have a convenient means to record feedback about these decisions and to provide other insights that will empower the employee to continuously improve the system.
Technology Stack Deep Dive
Our technology choices were driven by the need for rapid prototyping while maintaining a clear path to production scalability.
| Component | Current Technology | Future Plans | Reasoning |
|---|---|---|---|
| Agent Framework | LangChain + LangGraph | Continue + Custom Orchestration | Popular, proven framework. |
| Language Models | Gemini Flash 2.5 | Specialized Models + Ensembles | Easy to implement, fast and cost-effective for a foundation model |
| Data Storage | SQL Database | SQL + Vector Database (RAG) | Reliable for structured data, need semantic search |
| Monitoring | Custom Dashboard | Enhanced Analytics + ML Ops | Basic metrics covered, need deeper insights |
Key Design Challenges
Challenge 1: Time Constraints and Summer Program Design
A group of five people (one dropped out near the end) with various backgrounds was put together under a mentor and had eight weeks to conceive, design, and implement an AI product. With varying levels of technical ability, engagement, and commitment, it took a long time for everyone to agree to a concept, cutting our build time down to less than 4 weeks.
Not only did we need to complete a working demo in this period, we also needed to create a promotional video and prepare a formal pitch (along with demo) to present before a live audience and judges of various technical backgrounds (kind of like Shark Tank style).
Shortcuts had to be taken, and tradeoffs managed.
Limited Technical Expertise
Only 2 team members had programming experience, and nobody had programmed agents or LLMs before.
No Evaluation Framework
We basically had to test the models with simple batch runs of inputs and eyeballing the results.
No Real Data or Simulation Environment
We used LLMs to create mock data in a piecemeal fashion but did not have time to run simulations of the entire system working together.
Incomplete Implementation
We just ran out of time. Our frontend did not get connected to the backend. Our models are way too slow and need more tuning. Everything just needs more work.
• The sections below lay out the plan
Challenge 2: Competitive Differentiation
The core concepts of intelligent chatbot escalation and context integration could be easily replicated by competitors. Our differentiation must come from better execution, superior intelligence, and great user experience. Heavy use of foundation models provides no moat.
Our approach to this challenge focuses on two key areas:
Superior User Experience
Fast, seamless agent response times and effective interfaces for humans to both provide and receive context. Dashboards and embedded evaluation frameworks to effectively manage and tune the AI-human hybrid team.
Advanced Intelligence
Specialized models fine-tuned for specific aspects of customer service interactions, including effective ensembling of different models to better integrate context into every interaction, as well as a state of the art context managment system.
• UI Improvements
• Focus on more intelligent design and implementation of the escalation engine and context management engine
• Faster performance times (see Challenge 3 below)
Challenge 3: Real-time Performance
Customer service interactions happen in real-time. Any delays in our analysis or routing can negatively impact the user experience we're trying to improve.
Currently, all of our agents are probably too slow for real deployment; in particular, the SQL-based context retrieval in its current form is too slow for production use. We're addressing this through a multi-tiered approach:
Performance Optimization Strategy
Specialized, faster models and adding RAG capabilities to the context management system.
• Fast pre-screener models to detect quality issues before calling slower more robust models for consensus checks
• XGBoost model for fast ranking of human agent roster to each scenario
• Combining RAG for knowledge searches with SQL for recent activity searches
Challenge 4: Model Cost and Scalability
Using a foundation LLM for every interaction creates scaling challenges. As conversation volume grows, costs could become prohibitive, and latency already is a problem.
Our solution involves a graduated approach to model usage:
2. More robust models where necessary, such as final quality evaluation
3. Premium models only for complex edge cases
Future Roadmap
Our development roadmap is organized into three phases, each building on the lessons learned from the previous iteration:
Phase 1: Finish Basic Prototype
We need something more than the rudimentary Gradio demo to show off our system.
- Integrate FlashAPI to serve agents
- Connect to basic React frontend
- Deploy databases, agent workflows, and frontend to a cloud provider like AWS
Phase 2: Evaluation Framework
Especially with non-deterministic systems, the key to improvement and tuning is to rapidly iterate and experiment. We need a framework to make this happen.
- Implement a pre-deployment eval framework to select and tune each model
- Integrate the framework to evaluate post-deployment system changes
- Tune the existing models for optimum speed
Phase 3: Context Management Performance
Context searches are too slow for real production and are lacking in providing key information
- Integrate RAG/Vector Database for Knowledge Base searches
- Optimize SQL strategy and implementation
- Create a system to derive key information from SQL and transfer to RAG on a regular basis
- Acquire and/or simulate sufficient data for proper evaluation
Phase 4: Improved Models
Product not viable with significant improvements in performance, particularly speed/latency. There is no "moat" with foundation models.
- Fast local models
- Ensemble models for improved intelligence
- Use eval framework to select and tune models and optimize complete system
Technical Architecture Evolution
| Component | Phase 1 | Phase 2 | Phase 3 |
|---|---|---|---|
| Frustration Detection | Specialized sentiment models | Multi-modal emotion detection? | Predictive frustration modeling? |
| Quality Assessment | Hierarchical evaluation | Domain-specific rubrics? | Custom quality standards? |
| Human Routing | XGBoost + Context Ensemble | Deep Learning ensembles? | Reinforcement learning? |
| Context Management | RAG + SQL hybrid | Advanced semantic search | Knowledge graph integration |
Lessons Learned
Building VIA taught us several important lessons about developing AI systems:
1. Evaluation Framework to Quickly Iterate and Experiment
Just like with traditional ML, unless you can quickly iterate, experiment, and log results, it is difficult to improve the models and the system.
2. Speed is Relative
A couple of seconds of response time from a foundation LLM didn't seem that bad in certain situations, but in others, especially when compounded with multiple calls, it was not really practical. Frustration analysis, for example, needs to be super fast or it causes more frustration than what it addresses.
3. Optimizing Performance is Challenging
Balancing all the trade-offs including speed, accuracy, and cost is a unique challenge beyond software engineering, but it is also an opportunity to excel above the competition.
I plan to continue development of this project as both a portfolio project to demonstrate abilities as well as a learning platform as new concepts and technologies are implemented. I will write about these experiences here.
Discussion
More about certain decisions and my thought processes:
Depth
This was a really fun project in terms of Product Design and System Architecture, but because of the time constraints and because I was the only one handling much of the project, there was just not much depth in terms of AI engineering. By the time our team had finally coalesced around a product idea, it became a mad dash to try to finish a prototype in less than four weeks.
That is one reason why I plan to continue development on this project - so that I can get a better understanding of (and practice with) key AI engineering concepts.
I think this does highlight one of my key strengths though - I assimilate and process information well (better than the vast majority of people in my highly-biased, personal opinion):
- I can quickly see the "big picture (I came up with the design and architecture with no experience in LLMs)
- AND I can quickly figure out all the finer details
Code Base
Because of these time issues, the code base tends to be a lot of scaffolding and placeholders. I wanted to create a solid foundation that could be built upon, but there is still a lot of work to do and a lot of cleanup.
I relied a lot on Claude Code - both for rapid code generation and because I was completely new to LLM and agentic programming. I did not have time to sort out all the issues that this might have introduced, so the code base is definitely still a "work in progress".
OOP (Object-Oriented Programming)
I have done procedural programming for a long time but just started really using OOP a few months ago and quickly became a big fan because I think it has some key strengths when using an AI coding assistant:
- Modularity and Encapsulation - AIs tend to be over-eager and over-reaching, and discrete, modular classes and methods can help control this behavior by keeping everything in smaller, independent chunks.
- Abstract Interfaces - I like to create a mirror directory structure of just all the abstract interfaces - the AI can use this for context without having to absorb the entire code base with each prompt - a blueprint instead of a building.
- Building Blocks and Consistent Interfaces - Most programs need a few core modules like a Config Manager, Error Handler, and a Logger, and OOP makes it easier for AIs to just duplicate key modules from existing code bases.
- Dependency Injection, DI Containers, and Factories - DI containers and factory methods make it easy to abstract out and swap components without having to touch the primary code. The AI can keep adding capabilities by just adding different concrete implementations without risking the key code.
(I'm a complete OOP novice, so let me know if I'm misstating or not understanding something here.)
Agent Framework
I chose LangChain and LangGraph for our LLM and agent framework simply based on their popularity and the extensive documentation and examples available for LangChain. Nobody on our team had LLM or agent programming experience, and it was essentially a coin toss between this and CrewAI.
For rapid development in a an unfamiliar technology, I would be relying on Claude Code a lot. AI coding assistants do better with more popular technologies.
Models for Prototype
For our prototype with its time constraints, we chose to use a foundation model API to do all the heavy lifting since it would be easy to implement without too much tuning and deployment issues. Some of the factors we looked at in choosing a particular model included:
- Speed: Fast inference times crucial for user experience
- Cost Efficiency: Allows for rapid experimentation without budget constraints
- Versatility: Able to handle the various roles and tasks given to it
- Reliability: Avoid failures during testing and live demo runs
After some limited testing of other "fast, cheap models" like Sonnet Haiku, we settled on Gemini Flash 2.5 as our primary language model primarily because of speed.
Source Code
The complete source code for VIA is available on GitHub. As I mentioned above, this is still very much a "work in progess" that will likely undergo significant changes.
I did a lot of experimentation, and the code probably still has some artifacts of this that were abandoned or became obsolete.
 Repository Access
Repository Access
Project Structure
The codebase follows a scalable multi-agent design with clear separation of concerns:
├── agents/ # Agent-specific configurations
├── environments/ # Environment settings (dev/test/prod)
├── shared/ # Shared configuration files
└── config.yaml # Main configuration file
src/
├── core/ # Infrastructure & Configuration
│ ├── agent_config_manager.py
│ ├── context_manager.py
│ ├── database_config.py
│ └── logging/
├── interfaces/ # Contract-driven development
│ ├── core/
│ ├── nodes/
│ └── workflows/
├── nodes/ # AI Agent Implementations
│ ├── chatbot_agent.py
│ ├── quality_agent.py
│ ├── frustration_agent.py
│ ├── human_routing_agent.py
│ └── context_manager_agent.py
├── simulation/ # Testing & Validation Framework
│ ├── human_customer_simulator.py
│ ├── employee_simulator.py
│ └── demo_orchestrator.py
└── workflows/ # Orchestration & State Management
└── hybrid_workflow.py
The repository includes comprehensive documentation, setup instructions, and examples to help you understand and extend the VIA system (though I would wait until I got more completed before trying to extend it.)