NBA Prediction
End-to-end ML pipeline predicting NBA game winners with 62.1% accuracy (2024 season) using gradient boosting and real-time data integration
(2024-2025 NBA Season and Playoffs)
The Challenge
Build an end-to-end machine learning pipeline to predict the winners of NBA games:
- - Trains a model to predict game winners
- - Retrieves new data daily
- - Performs feature engineering on the data
- - Predict the probability of the home team winning
- - Display the results online
My Solution
Constructed a modular system that uses:
- - XGBoost, Optuna, and Neptune.ai for model training and experiment tracking
- - Github Actions, Selenium, and ScrapingAnt to scrape new games daily from NBA.com
- - Pandas to engineer features and store these
- - XGBoost and Sklearn to predict and calibrate winning probability
- - Streamlit to deploy online
Technical Highlights
Key innovations and technical achievements in this project
Advanced Modeling
XGBoost and LightGBM with Optuna hyperparameter tuning for optimal performance and Scikit-learn to calibrate probabilities
Feature Engineering
Created engineered features such as win streaks, losing streaks, home/away streaks, rolling averages for various time periods, and head-to-head stats
Data Pipeline
Automated ETL pipeline with error handling, data validation, and daily NBA.com scraping
Model Validation
Cross-validation and test set evaluation using stratified K-Folds and time-series K-Folds along with SHAP for interpretability and comparing feature importances between train and validation sets
Experiment Tracking
Neptune.ai integration for comprehensive experiment logging and model comparison
Production Ready
GitHub Actions CI/CD, Streamlit deployment with monitoring dashboard
Technology Stack
Tools and frameworks used throughout the project lifecycle
🐍 Core ML/Data
🚀 ML Models and Experimentation
📊 Data & Scraping
⚙️ MLOps and Deployment
Results & Impact
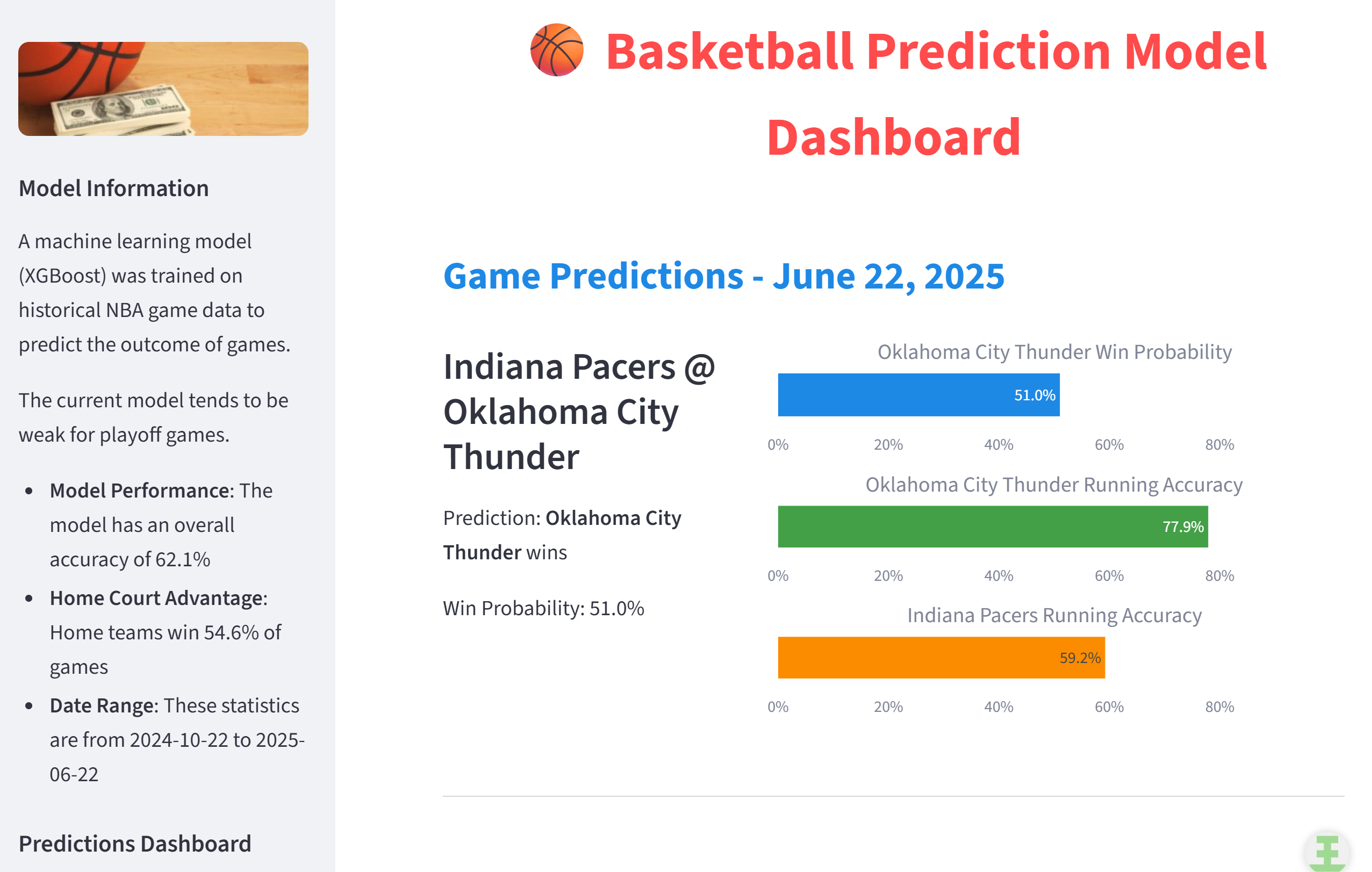
Season Results (2024-2025 NBA Season and Playoffs)
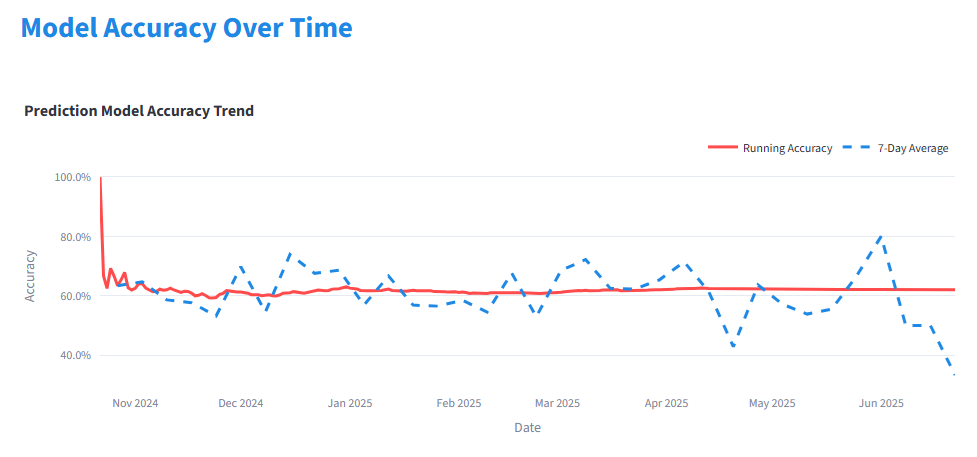
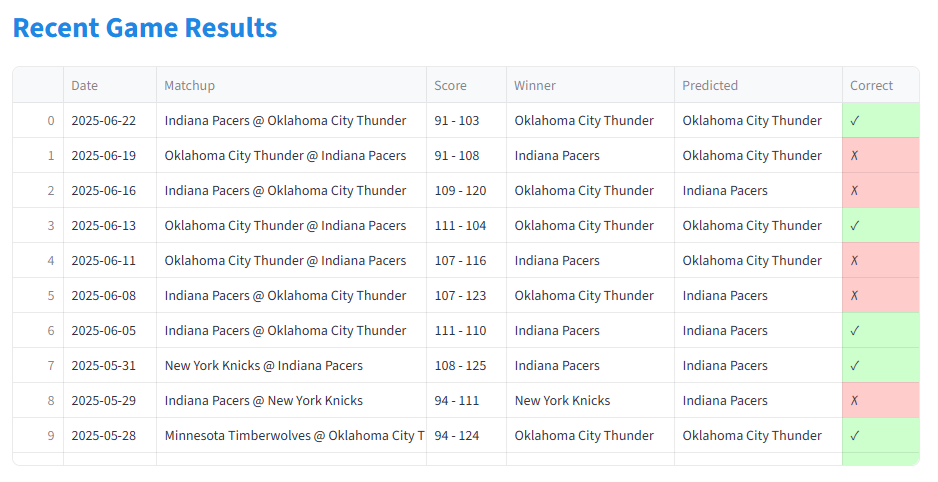
(As you can see, the model has issues with playoffs. The 7 day rolling averages have bigger swings during playoffs as teams play each other multiple times in a short span. This is an area of improvement for future iterations of the model.)
Lessons and Future Plans
This was my first big ML project and I learned a lot. So much in fact, that I am in the process of completely re-doing the project from scratch. I plan to write more about this at a certain point, but there are a couple of big takeaways.
Key Issues
Accuracy
My model had achieved an accuracy of 62.1% for the 2024 season. The baseline of "home team always wins" had an accuracy of 54.6%, but better models often achieve closer to 65%.
Last season, at least one expert at nflpickwatch.com achieved an accuracy of around 69.3%. Close to 100 got over 65%.
Reliability and Extensibility
Third-party services like Hopsworks, Neptune, and Streamlit at times would just stop working. Sometimes they would start back on their own, and sometimes I had to create a workaround. I abandoned Hopsworks altogether, and for Streamlit, I had to create a "light" dashboard-only repo.
Solutions
More Data, Feature Engineering, and Experimentation
Feature engineering is the key to improving the performance of any ML model. More advanced statistics are available on the NBA.com website that will be scraped to aid in the feature engineering, and a better evaluation framework will be used to facilitate faster experimentation to figure out which features work best.
Modular, OOP Architecture
A finer-grained, OOP approach with abstract interfaces and dependency injection makes it easier to swap-out problematic components and to add new capabilities. Alternates and fallbacks can be more easily incorporated into the pipeline.
🚧 Version 2 - In Development
I am currently working on a completely redesigned version of this project with improved architecture, better feature engineering, and enhanced reliability.
Architecture Highlights
Directory Structure
./ ├── configs/ │ ├── core/ │ │ ├── hyperparameters/ │ │ │ ├── catboost/ │ │ │ │ ├── baseline.json │ │ │ │ └── current_best.json │ │ │ ├── lightgbm/ │ │ │ │ ├── baseline.json │ │ │ │ └── current_best.json │ │ │ ├── pytorch/ │ │ │ │ └── baseline.json │ │ │ ├── sklearn_histgradientboosting/ │ │ │ │ ├── baseline.json │ │ │ │ └── current_best.json │ │ │ ├── sklearn_logisticregression/ │ │ │ │ ├── baseline.json │ │ │ │ └── current_best.json │ │ │ ├── sklearn_randomforest/ │ │ │ │ ├── baseline.json │ │ │ │ └── current_best.json │ │ │ └── xgboost/ │ │ │ ├── baseline.json │ │ │ └── current_best.json │ │ ├── models/ │ │ │ ├── catboost_config.yaml │ │ │ ├── lightgbm_config.yaml │ │ │ ├── pytorch_config.yaml │ │ │ ├── sklearn_histgradientboosting_config.yaml │ │ │ ├── sklearn_logisticregression_config.yaml │ │ │ ├── sklearn_randomforest_config.yaml │ │ │ └── xgboost_config.yaml │ │ ├── app_logging_config.yaml │ │ ├── model_testing_config.yaml │ │ ├── optuna_config.yaml │ │ ├── preprocessing_config.yaml │ │ └── visualization_config.yaml │ └── nba/ │ ├── app_config.yaml │ ├── data_access_config.yaml │ ├── data_processing_config.yaml │ ├── feature_engineering_config.yaml │ └── webscraping_config.yaml ├── data/ │ ├── cumulative_scraped/ │ │ ├── games_advanced.csv │ │ ├── games_four-factors.csv │ │ ├── games_misc.csv │ │ ├── games_scoring.csv │ │ └── games_traditional.csv │ ├── engineered/ │ │ └── engineered_features.csv │ ├── newly_scraped/ │ │ ├── games_advanced.csv │ │ ├── games_four-factors.csv │ │ ├── games_misc.csv │ │ ├── games_scoring.csv │ │ ├── games_traditional.csv │ │ ├── todays_games_ids.csv │ │ └── todays_matchups.csv │ ├── predictions/ │ │ ├── CatBoost_val_predictions.csv │ │ ├── LGBM_oof_predictions.csv │ │ ├── LGBM_val_predictions.csv │ │ ├── lightgbm_val_predictions.csv │ │ ├── SKLearn_HistGradientBoosting_val_predictions.csv │ │ ├── SKLearn_RandomForest_val_predictions.csv │ │ ├── XGBoost_oof_predictions.csv │ │ ├── XGBoost_val_predictions.csv │ │ └── xgboost_val_predictions.csv │ ├── processed/ │ │ ├── column_mapping.json │ │ ├── games_boxscores.csv │ │ └── teams_boxscores.csv │ ├── test_data/ │ │ ├── games_advanced.csv │ │ ├── games_four-factors.csv │ │ ├── games_misc.csv │ │ ├── games_scoring.csv │ │ └── games_traditional.csv │ └── training/ │ ├── training_data.csv │ └── validation_data.csv ├── docs/ │ ├── commentary/ │ │ └── Webscraping.md │ ├── data/ │ │ ├── column_mapping.json │ │ └── nba-boxscore-data-dictionary.md │ ├── src/ │ │ └── readme.md │ └── readme.md ├── hyperparameter_history/ │ ├── LGBM_history.json │ └── XGBoost_history.json ├── notebooks/ │ ├── baseline.ipynb │ └── eda.ipynb ├── docs/ │ ├── AI/ │ │ ├── config_reference.txt │ │ ├── config_tree.txt │ │ ├── directory_tree.txt │ │ └── interfaces.md │ ├── commentary/ │ │ └── Webscraping.md │ ├── data/ │ │ ├── column_mapping.json │ │ └── nba-boxscore-data-dictionary.md │ ├── src/ │ │ └── readme.md │ └── readme.md ├── hyperparameter_history/ │ ├── LGBM_history.json │ └── XGBoost_history.json ├── noteboooks/ │ ├── baseline.ipynb │ └── eda.ipynb ├── src/ │ ├── ml_framework/ │ │ ├── core/ │ │ │ ├── app_file_handling/ │ │ │ │ ├── app_file_handler.py │ │ │ │ └── base_app_file_handler.py │ │ │ ├── app_logging/ │ │ │ │ ├── app_logger.py │ │ │ │ └── base_app_logger.py │ │ │ ├── config_management/ │ │ │ │ ├── base_config_manager.py │ │ │ │ ├── config_manager.py │ │ │ │ └── config_path.yaml │ │ │ ├── error_handling/ │ │ │ │ ├── base_error_handler.py │ │ │ │ ├── error_handler.py │ │ │ │ └── error_handler_factory.py │ │ │ └── common_di_container.py │ │ ├── framework/ │ │ │ ├── data_access/ │ │ │ │ ├── base_data_access.py │ │ │ │ └── csv_data_access.py │ │ │ ├── data_classes/ │ │ │ │ ├── metrics.py │ │ │ │ ├── preprocessing.py │ │ │ │ └── training.py │ │ │ └── base_data_validator.py │ │ ├── model_testing/ │ │ │ ├── experiment_loggers/ │ │ │ │ ├── base_experiment_logger.py │ │ │ │ ├── experiment_logger_factory.py │ │ │ │ └── mlflow_logger.py │ │ │ ├── hyperparams_managers/ │ │ │ │ ├── base_hyperparams_manager.py │ │ │ │ └── hyperparams_manager.py │ │ │ ├── hyperparams_optimizers/ │ │ │ │ ├── base_hyperparams_optimizer.py │ │ │ │ ├── hyperparams_optimizer_factory.py │ │ │ │ └── optuna_optimizer.py │ │ │ ├── trainers/ │ │ │ │ ├── base_trainer.py │ │ │ │ ├── catboost_trainer.py │ │ │ │ ├── lightgbm_trainer.py │ │ │ │ ├── pytorch_trainer.py │ │ │ │ ├── sklearn_trainer.py │ │ │ │ ├── trainer_factory.py │ │ │ │ ├── trainer_utils.py │ │ │ │ └── xgboost_trainer.py │ │ │ ├── base_model_testing.py │ │ │ ├── di_container.py │ │ │ ├── main.py │ │ │ └── model_tester.py │ │ ├── preprocessing/ │ │ │ ├── base_preprocessor.py │ │ │ └── preprocessor.py │ │ ├── uncertainty/ │ │ │ └── uncertainty_calibrator.py │ │ └── visualization/ │ │ ├── charts/ │ │ │ ├── base_chart.py │ │ │ ├── chart_factory.py │ │ │ ├── chart_types.py │ │ │ ├── chart_utils.py │ │ │ ├── feature_charts.py │ │ │ ├── learning_curve_charts.py │ │ │ ├── metrics_charts.py │ │ │ ├── model_interpretation_charts.py │ │ │ └── shap_charts.py │ │ ├── exploratory/ │ │ │ ├── base_explorer.py │ │ │ ├── correlation_explorer.py │ │ │ ├── distribution_explorer.py │ │ │ ├── team_performance_explorer.py │ │ │ └── time_series_explorer.py │ │ └── orchestration/ │ │ ├── base_chart_orchestrator.py │ │ └── chart_orchestrator.py │ └── nba_app/ │ ├── data_processing/ │ │ ├── base_data_processing_classes.py │ │ ├── di_container.py │ │ ├── main.py │ │ └── process_scraped_NBA_data.py │ ├── feature_engineering/ │ │ ├── base_feature_engineering.py │ │ ├── di_container.py │ │ ├── feature_engineer.py │ │ ├── feature_selector.py │ │ └── main.py │ ├── webscraping/ │ │ ├── old/ │ │ │ ├── test_websraping.py │ │ │ └── webscraping_old.py │ │ ├── base_scraper_classes.py │ │ ├── boxscore_scraper.py │ │ ├── di_container.py │ │ ├── main.py │ │ ├── matchup_validator.py │ │ ├── nba_scraper.py │ │ ├── page_scraper.py │ │ ├── readme.md │ │ ├── schedule_scraper.py │ │ ├── test.ipynb │ │ ├── test_page_scraper.py │ │ ├── utils.py │ │ └── web_driver.py │ └── data_validator.py ├── tests/ │ ├── ml_framework/ │ └── nba_app/ │ └── webscraping/ │ ├── test_boxscore_scraper.py │ ├── test_integration.py │ ├── test_nba_scraper.py │ ├── test_page_scraper.py │ └── test_schedule_scraper.py ├── directory_tree.txt ├── pyproject.toml ├── README.md └── uv.lock
Key Design Principles
Clean, layered architecture
src/ml_frameworkvssrc/nba_appenforces a strict one-way dependency (nba_app → ml_framework), keeping the platform generic and the domain isolatedsrc/package layout with__init__.pyenables clean imports and scalable growth across modules
SOLID principles throughout
- Single Responsibility: Modules like
src/ml_framework/core/config_management/,app_logging/,error_handling/each own one concern; nba_app partitions data_processing, feature_engineering, and webscraping - Open/Closed: Trainers (
src/ml_framework/model_testing/trainers/), experiment loggers (experiment_loggers/), and data access (framework/data_access/) are extended via factories without modifying existing code - Liskov Substitution: Abstract base classes (e.g.,
BaseTrainer,BaseExperimentLogger,BaseDataAccess,BasePreprocessor) guarantee drop-in interchangeability of implementations - Interface Segregation: Focused interfaces (e.g., separate
BaseTrainer,BaseModelTester,BaseHyperparamsOptimizer,BaseChart) prevent "fat" dependencies - Dependency Inversion: High-level flows depend on abstractions; concrete classes are resolved via
di_container.pyfiles in nba_app and ml_framework
Interchangeable, plug-and-play components
- Experiment tracking:
BaseExperimentLogger+experiment_logger_factorywithmlflow_logger.py; easily swap to W&B or a custom tracker by adding a new implementation - Models/trainers:
trainer_factoryorchestratescatboost_trainer.py,lightgbm_trainer.py,xgboost_trainer.py,sklearn_trainer.py,pytorch_trainer.py—all behindBaseTrainer - Hyperparameter search:
BaseHyperparamsOptimizerwithoptuna_optimizer.py; optimizer factory allows alternative HPO backends without touching call sites - Data access:
BaseDataAccesswithcsv_data_access.py—swap in a DB-backed implementation transparently - Visualization:
BaseChartandchart_factorysupport consistent chart creation; new charts plug in without refactoring call sites - Web scraping:
BaseWebDriver,BasePageScraper, andBaseNbaScraperin nba_app/webscraping allow switching drivers, parsers, or sources via config
Centralized, declarative configuration
configs/coreandconfigs/nbaseparate platform defaults from NBA-specific settings- Fine-grained YAMLs for models, preprocessing, logging, Optuna, and visualization; hyperparameters are versioned in
configs/core/hyperparameterswithcurrent_best.jsonandbaseline.jsonper model config_tree.txtdocuments the effective configuration namespace for full transparency and reproducibility
Reproducibility and environment parity
uv.lockpins dependencies;pyproject.tomlconsolidates build/runtime metadata.gitignore/.gitattributesmaintain clean VCS state;data/directories are staged but not versioned
Testable, CI-friendly codebase
tests/mirrors package structure, with unit and integration tests for webscraping and room to expand for platform_core- Smaller classes and functions under
src/enable targeted unit tests that were not possible with notebooks
Robust observability and error handling
- Structured logging via
src/ml_framework/core/app_loggingwith rolling files and console output, fully configured fromconfigs/core/app_logging_config.yaml - Centralized error handling in
src/ml_framework/core/error_handlingwith factory-based resolution for consistent behavior
End-to-end ML workflow discipline
- Deterministic model testing in
src/ml_framework/model_testingwith TimeSeriesSplit, OOF, validation-set testing, and SHAP integration—configured inconfigs/core/model_testing_config.yaml - Hyperparameter history tracked in
hyperparameter_history/for auditability and reproducibility
Clear research-to-production path
notebooks/quarantines exploratory work; production code resides insrc/data/is organized by lifecycle (newly_scraped, cumulative_scraped, processed, engineered, training, predictions), making pipelines explicit and debuggable
Extensible visualization and interpretability
src/ml_framework/visualizationprovides base interfaces, orchestration, and specialized chart sets (feature importance, learning curves, metrics, SHAP), all toggled viaconfigs/core/visualization_config.yaml
Domain expansion without rework
- Three-tier architecture and one-way dependencies enable adding new sports apps (e.g.,
mlb_app) reusing ml_framework unchanged
 View Version 1 Repository
View Version 1 Repository
SOLID in Practice
ABCs + Factories + Config-first wiring
Single Responsibility Principle (SRP)
Each module has one reason to change.
- Configuration:
src/ml_framework/core/config_management/handles only config discovery/merge/access (BaseConfigManager, ConfigManager) - Logging:
src/ml_framework/core/app_logging/focuses on structured logging (BaseAppLogger, AppLogger) configured viaconfigs/core/app_logging_config.yaml - Error handling:
src/ml_framework/core/error_handling/centralizes error policies (BaseErrorHandler, ErrorHandler, ErrorHandlerFactory) - Domain slices: nba_app is split into data_processing, feature_engineering, and webscraping, each with their own DI containers and mains
Open/Closed Principle (OCP)
Extend via new classes/factories without modifying existing code.
- Trainers: Add a new trainer under
src/ml_framework/model_testing/trainers/and register viatrainer_factory.py, no orchestrator changes - Experiment logging: Implement BaseExperimentLogger and hook into
experiment_logger_factory.pyto support W&B or custom loggers alongsidemlflow_logger.py - Data access: Implement BaseDataAccess (
framework/data_access/) to add DB, cloud, or parquet backends next tocsv_data_access.py - Charts: Add a new chart under
visualization/charts/and expose it viachart_factory.py; orchestrators don't change
Liskov Substitution Principle (LSP)
Abstract base classes guarantee drop-in compatibility.
- BaseTrainer subclasses (
catboost_trainer.py,lightgbm_trainer.py,xgboost_trainer.py,sklearn_trainer.py,pytorch_trainer.py) can be swapped without breakingmodel_tester.py - BaseExperimentLogger implementations (
mlflow_logger.pytoday) can be replaced by any logger honoring the same interface - BaseDataAccess and BasePreprocessor enforce method contracts so downstream code doesn't care about concrete types
Interface Segregation Principle (ISP)
Small, focused interfaces prevent unnecessary coupling.
- Separate interfaces for training (BaseTrainer), model testing (BaseModelTester), HPO (BaseHyperparamsOptimizer), validation (BaseDataValidator), preprocessing (BasePreprocessor), and visualization (BaseChart, BaseChartOrchestrator)
- Web layer uses granular abstractions: BaseWebDriver, BasePageScraper, BaseNbaScraper—scrapers don't inherit heavy methods they don't use
Dependency Inversion Principle (DIP)
High-level policies depend on abstractions, not concretions.
- Factories and DI:
experiment_logger_factory.py,trainer_factory.py,hyperparams_optimizer_factory.py, anddi_container.pyfiles supply concrete instances to code that only references base interfaces - Config-driven wiring:
configs/core/model_testing_config.yamlselects models, logging, and preprocessing; code reads the abstractions and resolves implementations at runtime - One-way dependency rule: nba_app depends on ml_framework; ml_framework stays domain-agnostic, keeping policies at the top and details at the bottom
Bonus: Interchangeability by Design
- Experiment tracker is MLflow today (
model_testing/experiment_loggers/mlflow_logger.py) but it sits behind BaseExperimentLogger andexperiment_logger_factory.py—swap to W&B or a homegrown tracker by adding one class and a factory entry - Trainers, HPO backends, data access layers, and chart types are all selected via configuration and factories, not hard-coded conditionals—making replacement low-risk and testable